Spark Kafka Docker Configuration
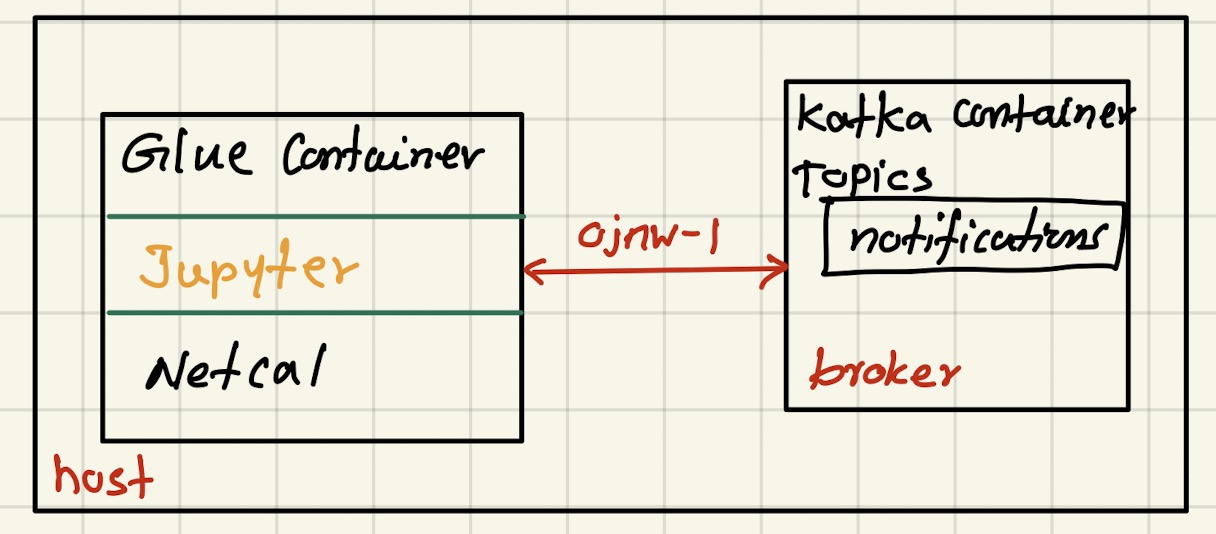
This is the continuation of the [Spark Streaming Basics](/apache%20spark/2023/06/09/Spark-Streaming-part-1.html). I explained the basic stream example, which runs only on one AWS Glue container. The stream producer was Netcat, and the sink was a text file. In this post, the stream producer is still Netcat, but the sink is Kafka. Both Kafka and Spark running on Docker containers.
It is important to separate the producer, processor and sink from each other. However, in this case, as in the previous post, Netcat still run in the Glue container where Spark producer as it is.
Here is the new Kafka container docker-compose.yml file:
---
version: '3'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.3.2
container_name: zookeeper
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-kafka:7.3.2
container_name: broker
ports:
# To learn about configuring Kafka for access across networks see
# https://www.confluent.io/blog/kafka-client-cannot-connect-to-broker-on-aws-on-docker-etc/
- "9092:9092"
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_INTERNAL:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:9092,PLAINTEXT_INTERNAL://broker:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
networks:
default:
external:
name: ojnw-1
In the above file, line# 24, instead of localhost, must be replaced by the broker. In addition to that, it is important to notice that both the Glue container (Spark) and Kafka container share the same network, ojnw-1. You need to create this network in your host:
# to create
docker network create ojnw-1
# to verify
docker network ls
In the Jupyter Scal notebook, first create the Spark session:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder().
master("local[3]").
appName("Kafka Test").
config ("spark.streaming.stopGracefullyOnShutdown", "true").
config ("spark.sql.shuffle.partitions",3).
getOrCreate()
It is better to avoid deleting the checkpoint each and every restart of the notebook:
import java.text.SimpleDateFormat
import java.util.Date
val dateFormatter = new SimpleDateFormat("dd-MM-yyyy-hh-mm-aa")
val dateprefix = dateFormatter.format(new Date())
Load the stream and start:
import org.apache.spark.sql.functions._
val lineDF = spark.readStream.
format("socket").
option("host", "localhost").
option("port", "9999").
load()
val outDF = lineDF.
writeStream.
format("kafka").
option("kafka.bootstrap.servers", "broker:9092").
option("topic", "notifications").
outputMode("append").
option("checkpointLocation", s"chk-point-dir-$dateprefix").
start()
outDF.awaitTermination()
As shown in line #11, the Glue container can access broker created by docker-compose.yml.
After configuring the docker container, log in as a root user.
docker exec -it --user root broker bash
install the net-tools
yum install net-tools
To list the ports in the Kafka broker container
netstat -an
If you need more investigation, run the test client1
docker run --network=ojnw-1 --rm --name python_kafka_test_client --tty python_kafka_test_client broker:9092
To list the Kafka topics (host machine bash):
docker exec broker kafka-topics --list --bootstrap-server broker:9092
Read from the Kafka topic (host machine bash)
docker exec --interactive --tty broker \
kafka-console-consumer --bootstrap-server broker:9092 \
--topic notifications \
--from-beginning
Your consumer will display whatever text type in the Netcat.
Reference